In the world of version control, branching plays a crucial role in software development, enabling teams to work in parallel, experiment, and manage changes efficiently without disrupting the main codebase. A branch acts as a pointer to a specific commit, providing a separate environment to develop features, fix bugs, or try new ideas. To maintain a well-organized and smooth development process, branching strategies are essential—they outline the rules and conventions for creating, managing, and merging branches. By adopting an effective branching strategy, teams can ensure a streamlined workflow, enhance collaboration, and make integrating code changes more predictable and manageable. This post will explore the fundamentals of branches, branching strategies, and how these concepts help keep your codebase clean and efficient as your project evolves.
Definitions:
Branch: A pointer to a specific commit. Branches allow for parallel development and experimentation.
Branching Strategy: A set of rules or conventions that dictate how branches should be created, used, managed, and merged in a version control environment. This strategy helps manage development processes, ensuring systematic updates and integration of features, bug fixes, and other changes without disrupting the main codebase. Effective branching strategies enable easier collaboration among development teams and smoother workflow in deploying code changes.
Commit Hash: A unique identifier for each commit. It is a 40-character string composed of hexadecimal characters (0-9 and a-f) and calculated based on the contents of a directory tree in Git. This hash is produced by the SHA-1 algorithm.
Conflict: A situation where Git cannot automatically merge changes between branches.
Code Review: A systematic examination of software source code, conducted by developers, to find and fix mistakes overlooked during the initial development phase, improving both the overall quality of software and the developers’ skills.
Main: The default branch name in many Git repositories, particularly in new repositories initialized on platforms like GitHub that have adopted this name in 2020 for inclusivity.
Master: Traditionally the default branch name in many Git repositories. This name is still the default in Git unless changed via the init.defaultBranch setting. Since GitHub adopted main in 2020 most Source Code Platforms set the default branch name to main. In this article, I will exclusively reference the default branch as main.
Merge: the process of integrating changes from one branch into another branch.
History: The sequence of commits made to a repository over time. Each commit represents a snapshot of the project at a specific point in time and includes a unique identifier (the commit hash), the changes made in that commit, the timestamp, and the author’s information. This allows you to track the evolution of your project, and see what changes were made, when, and by whom.
What is a Branch?
Branches allow developers to write code without affecting the primary code base until the developer is ready to introduce the new code. Branching is one of the most fundamental and most daunting features of Git for new users. All repositories are initialized with a default branch which we will reference as main. By “Branching” off of the original code base the developer can make changes and test those changes without breaking the code or creating blockages for the rest of the team. Because the code is created separately from the other developers’ work it is necessary to put testing and administrative processes in place to ensure that the code can be merged back into main branch with no problems.
Every branch is just a pointer to a specific commit that is tracked inside a hidden folder in each repo. However, the .git folder is treated as a hidden file system object so you must adjust your file browser settings or use the command line to see the internal git files.
On a Linux operating system, this would look like
ls –all
On a Windows operating system, this would look like
dir /a:h
If you cd into the directory .git > refs > heads you will find a file for any branch that exists in the local repository excluding main. If you open each file in a text editor you will see that each file has exactly 1 line containing a hash for the most recent commit to the branch. It should look like this:
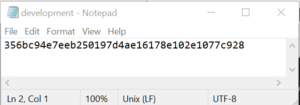
That’s all a branch is. A file that has a hash. Why does this matter and what does it mean? Git at its most fundamental relies on commit hashes to create a chain of commits and through that chain – trace history.
The commit hash is crucial for the functioning of Git branches for several reasons:
- Uniqueness: Each commit has a unique hash, which means you can refer to it unambiguously. This is particularly useful when you want to check out a specific commit or view the changes introduced by it.
- Immutability: Once a commit is created, its hash never changes. This means that the history of commits is immutable. You can always go back to the previous state of your project by checking out a specific commit using its hash.
- Linking Commits: Each commit in Git contains a reference to its parent commit(s) by storing their hashes. This forms a chain of commits, which is essentially what a branch is. When you create a new branch, Git creates a new pointer for the same commit hash you are currently using.
- Detecting Changes: If a small part of a commit changes, its hash will change completely. This makes it easy to detect changes or corruption.
- Merging: When branches are merged, Git uses these hashes to determine which changes have been made in each branch and to resolve conflicts.
Why use Branching?
When more than one developer is working on the same repository it can be really hard to not step on other people’s toes as well as keep a clean history of changes. Branching is the solution but how you implement it into a development workflow – Branching Strategies – depends on the team’s complexity. There are two common patterns used by teams to manage their processes. While these are very common strategies it is highly recommended that you build a strategy around your team and solution rather than the other way around.
For teams that have simple code changes that are simple for a human to read and do a manual code review on then the strategy known as GitHub Flow is likely to be the best strategy. There’s only one main branch, and every new feature or bug fix is developed on a separate branch. Once the changes are reviewed and tested, they are merged back into main branch and deployed. Before the code is merged back into main it is recommended to run tests and communicate about the changes in a code review. Because of the simplicity of this branching strategy, it is the best fit for teams that are creating simple applications working on a simple team structure.
If the code updates are complex or larger than a human can comprehend easily then a branching strategy formally referred to as GitFlow will be a better fit for the team’s needs. This strategy involves having two main branches, development and master. Additional branches are created for developing new features and for release preparation and are merged into the development branch instead of main. The develop branch is used for integration and testing of new features, while the master branch reflects the production-ready state. Because of the extra long-standing branch, development, between the feature branch and main branch, this allows for more intensive testing on the code base before it is merged into main.
How do I create a branch?
Because of its simplicity, we will walk through a simple example of GitHub flow below in our example of how to create a branch.
Open up the git command prompt in the folder for your git repository and right-click> git bash here. To create a new branch named BranchName use the command below
git branch BranchName
After creating the branch there is one more step before making changes. To switch to the new branch you must first checkout the branch.
git checkout BranchName
Congrats you created your first branch! You can add code and make commits as needed.
How do I merge my new code into main?
After you have the new branch in a state that is ready to be merged into the primary code base. In a pure git world, you can just merge your new branch into main, however, most source code platforms have a process for code reviews. During the review, all sorts of activities can be required from human review, automatic testing, or even linters for formatting code. While all of these are great ideas the bare minimum is a review of the code from a peer to confirm the code being added is necessary and functional. After the code review is approved most source code platforms will run the below command for you:
First move from your new branch to main branch by checking out the branch
git checkout main
Then merge the new branch into main
git merge BranchName
Under most circumstances, this is the end of the process of adding new features to an existing code base. In the next section, we will deep dive into how commits work, the different types of merges, and more git internals. In the next post we will deep dive into how commits and merges work, the different merge types, and what happens when merges conflict.