Unless you’ve lived in a cave for the last few months, you’ve heard of ChatGPT. It’s a deep-learning model (neural network) created by OpenAI whose ability to generate human-like prose has made AI the topic of dinner-table conversations around the world. Here’s an example in which I asked it to explain molecular biology in the style of Dr. Seuss:
Molecular biology is a funny thing,
It looks at the cells with a dingle-ding,
It studies the parts that make up the whole,
Like proteins and DNA with a roll and a toll.
It looks at the way that genes are expressed,
How the proteins interact and how they’re blessed,
It looks at the structure and the way it’s made,
And how it’s all connected like a jigsaw parade.
You can try ChatGPT yourself by pointing your browser to https://chat.openai.com/chat and typing a prompt such as “Write a short story that begins with it was a dark and stormy night.” You’ll have to create an account if you don’t already have one, but the account doesn’t have to be paid for. You get a certain number of free credits each month, and you can do a lot with those free credits.
ChatGPT isn’t limited to generating prose; it can produce code, too. Here’s how it responded when I prompted it to “Create a Python function that accepts an array of numbers as input, bubble sorts the numbers, and returns a sorted array:”
def bubble_sort(arr):
n = len(arr)
# Traverse through all numbers in array
for i in range(n):
# Last i elements are already sorted
for j in range(0, n - i - 1):
# Traverse through the array from 0 to n-i-1
# Swap if the element found is greater than the next element
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
If Python isn’t your thing, ChatGPT understands dozens of other programming languages, too. You can even feed it code written in one language and ask it to convert it to another or ask it to comment on your raw source code files.
So exactly what is ChatGPT? How was it built, and how does it work? The best way to explain ChatGPT is to start at the beginning. And the beginning, in this case, goes back to 2017.
From LSTMs to Transformers
ChatGPT falls under the branch of deep learning known as natural language processing, or NLP. NLP encompasses a variety of activities, including text classification (sentiment analysis and spam filtering, for example), keyword extraction, named-entity recognition, document summarization, and question answering – posing a question in plain English and searching a corpus of text for an answer. One of the more ambitious tasks to which NLP is applied is neural machine translation, or NMT, which translates text into other languages.
Until 2017, most NMT models, including the one that powered Google Translate, were recurrent neural networks. RNNs use Long Short-Term Memory (LSTM) cells to factor word order into their calculations. They understand, for example, that “Park the car down the street” and “The car park down the street” have two different meanings. Per the illustration below, which comes from a paper published by Google engineers in 2016, the Google Translate of that era used consecutive layers of LSTM cells to encode phrases to be translated, and another stack of LSTM cells to decode them into the target language. An attention module positioned between the encoder and decoder helped zero in on a sentence’s most important words.
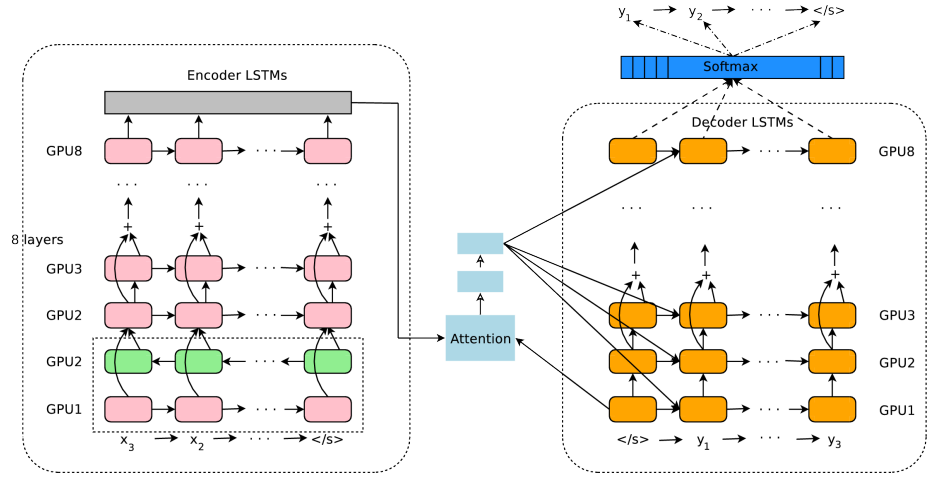
Google Translate circa 2016
In 2017, a landmark paper titled “Attention Is All You Need” changed the way data scientists approach NMT and other NLP tasks. That paper proposed a better way to process language based on transformer models that eschew LSTMs and use neural attention mechanisms to model the context in which words are used. Transformer models are superior to LSTM models in several ways, not the least of which is that they can infer meaning from text samples of any size (by contrast, as text length grows, an RNN’s power to connect related words diminishes) and they can be trained in parallel on multiple GPUs. Today, transformer models have almost entirely replaced LSTM-based models, particularly in the field of NLP. They also play an ever-increasing role in computer vision, particularly in models that generate images from textual descriptions.
The diagram below comes from the aforementioned paper and documents a transformer encoder-decoder architecture that supports neural machine translation, among other tasks. (It also depicts the core architecture of ChatGPT.) The model has two inputs. On the left is a transformer that encodes text input to it into arrays of floating-point numbers that capture meaning. On the right is a transformer that takes the output from the encoder and a second text input and decodes them into a set of probabilities that predicts the next word in the second input. When translating English to French, the first text input is the English phrase to be translated. The second text input is the French translation generated so far. The model operates iteratively, first generating the first word in the translation, then the second, and so on. Much of the magic lies in the multi-head attention layers, which use the self-attention mechanism described in the paper to model relationships between words independent of the input length.
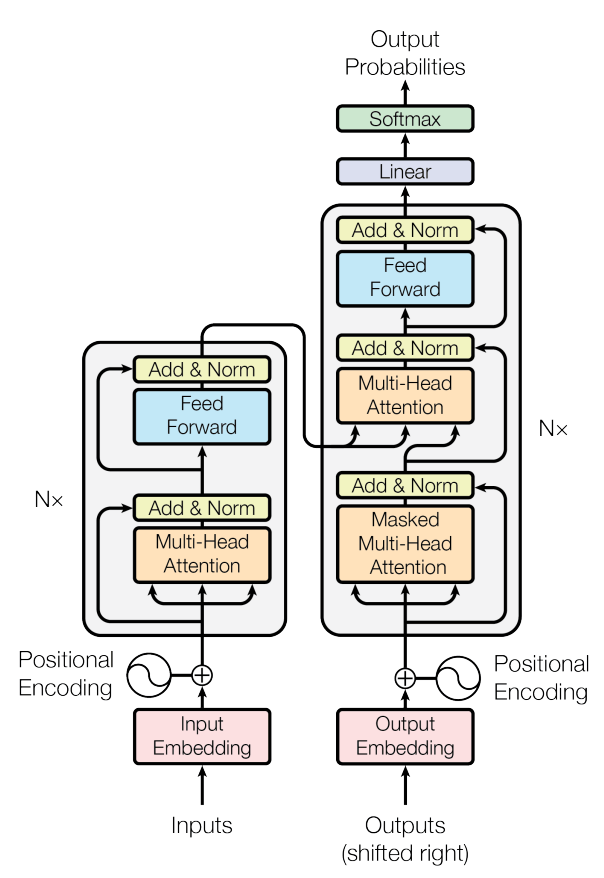
Transformer encoder-decoder architecture
Chapter 13 of my book “Applied Machine Learning and AI for Engineers” features the source code for a working transformer-based NMT model. It does a credible job of translating short sentences written in English to French given that it was trained on just 50,000 phrase pairs: short English sentences and their French equivalents Here’s a sample of the training data. Note the special tokens denoting the start and end of the French phrases:
| He heard the noise | [start] Il entendit le bruit [end] |
| He heard the sound | [start] Il a entendu le son [end] |
| He held his breath | [start] Il a retenu sa respiration [end] |
| He held his breath | [start] Il a retenu son souffle [end] |
| He is a bank clerk | [start] Il est employé de banque [end] |
| He is a bus driver | [start] Il est conducteur de bus [end] |
| I think you’re cute | [start] Je pense que tu es mignonne [end] |
| I think you’re cute | [start] Je pense que vous êtes adorable [end] |
| Are you a good golfer | [start] Êtes-vous bon golfeur [end] |
| Are you a good golfer | [start] Es-tu une bonne golfeuse [end] |
Like the encoder-decoder in the diagram, my model has two inputs. One accepts an English phrase, the other a partially completed French phrase. The process of translating “hello world” into French is pictured below. You first input “hello world” to the English input and “[start]” to the French input. The model predicts the next word in the French translation by assigning a probability to every word in its French vocabulary – in this example, about 12,000 words – based on the corpus of text that it was trained with and picking the word with the highest probability. Then you call the model again, this time passing “hello world” to the English input and “[start] salut” to the French input. You repeat this process until the next predicted word is “[end]” denoting the end of the translation.
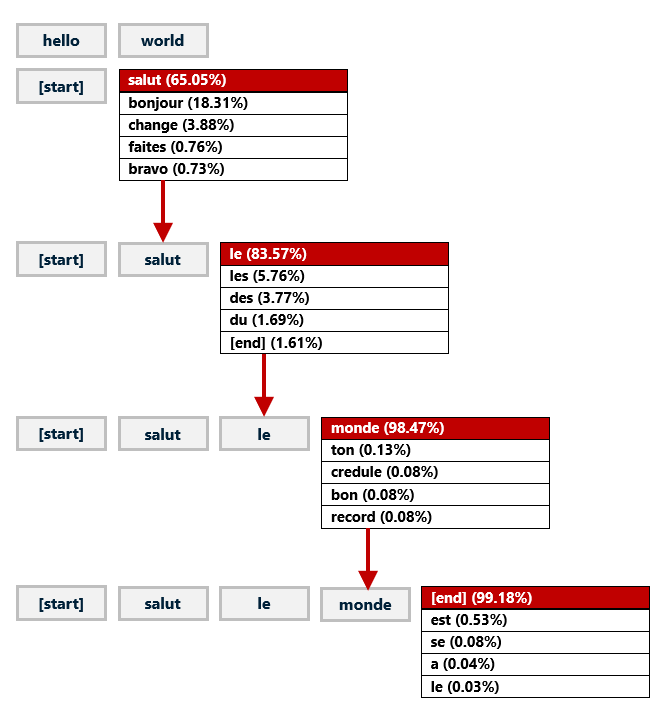
How a neural network translates English to French
The model can translate phrases it has never seen because it learned the mechanics of translating English to French from the 50,000 training samples. It’s not perfect, but the more data it’s trained with, the more capable it becomes. Google Translate was trained on more than 25 billion phrase pairs in over 100 languages, which explains why it rivals a human’s ability to translate text.
Learn more about our Azure services
Bidirectional Encoder Representations from Transformers (BERT)
Building models like Google Translate is expensive. First, you have to collect (or manufacture) billions of lines of training data. Then you need massive amounts of compute power to do the training. Models like these often require weeks to train on hundreds of graphics processing units (GPUs) or tensor processing units (TPUs) costing $10,000 or more each. But the introduction of transformers in 2017 laid the groundwork for another landmark innovation in the NLP space: Bidirectional Encoder Representations from Transformers, or BERT for short. Introduced by Google researchers in a 2018 paper titled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, BERT advanced the state of the art by providing pre-trained transformers that can be fine-tuned for a variety of NLP tasks.
Google instilled BERT with language understanding by training it with more than 2.5 billion words from Wikipedia articles and 800 million words from Google Books. Training required four days on 64 TPUs. BERT isn’t generally useful by itself, but it can be fine-tuned to perform specific tasks such as sentiment analysis or question answering. Fine-tuning is accomplished by further training the pre-trained model with task-specific samples at a reduced learning rate, and it is much less expensive and time-consuming than training BERT from scratch. It’s as if you’re running a 26-mile marathon and BERT spots you the first 25 miles.
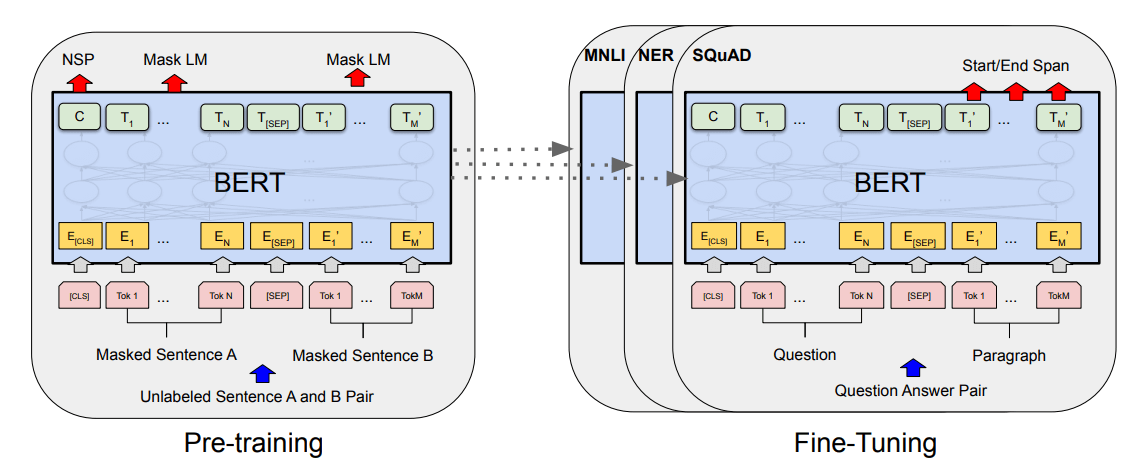
BERT as a base model for fine-tuning
Aside from the fact that it was trained with a huge volume of text, the key to BERT’s ability to understand human language is an innovation known as Masked Language Modeling. MLM turns a large corpus of text into a training ground for learning the structure of a language. When BERT models are pretrained, a specified percentage of the words in each batch of text – usually 15% – are randomly removed or “masked” so the model can learn to predict the missing words from the words around them. Unidirectional models look at the text to the left or the text to the right and attempt to predict what the missing word should be. MLM uses text on the left and right to inform its decisions. That’s why BERT is a “bidirectional” transformer. A model has a better chance of predicting what word should fill in the blank in the phrase “Every good ____ does fine” than it has at predicting the next word in the phrase “Every good ____.” The answer could be boy, as in “Every good boy does fine,” or it could be turn, as in “Every good turn deserves another.” Or it could be something else entirely.
Next-word prediction is the super power that drives text generators such as ChatGPT. Thanks to MLM, deep-learning models can learn to predict the next word in a sentence without labeled datasets. That’s important, because creating labeled data is time-consuming – especially when it involves billions of samples.
BERT has been called the “Swiss Army knife” of NLP. Google uses it to improve search results and predict text as you type into a Gmail or Google Doc. Dozens of variations have been published, including DistilBERT, which retains 97% of the accuracy of the original model while weighing in 40% smaller and running 60% faster. Also available are variations of BERT already fine-tuned for specific tasks such as question answering. Such models can be further refined using domain-specific datasets, or they can be used as is.
If you’re a programmer and you’re curious to know what BERT fine-tuning looks like, my book offers an example. But 2018 was a long time ago. ChatGPT doesn’t rely on fine-tuned versions of BERT. The next section explains why.
From BERT to ChatGPT
BERT was the world’s first Large Language Model (LLM). It featured around 345 million parameters, which is a measure of the size and complexity of a neural network. (Think of an equation that has 345 million terms. That’s a big equation!) OpenAI followed Google’s lead and produced BERT-like LLMs of their own in 2018 and 2019: first GPT-1 with 117 million parameters, and then GPT-2 with 1.5 billion parameters. In 2020, OpenAI rocked the NLP world by releasing GPT-3 featuring a whopping 175 billion parameters, earning it the title of the largest LLM, indeed the largest neural network, ever built. March 2023 saw the release of GPT-4, which builds on GPT-3. At the time of this writing, OpenAI hasn’t revealed GPT-4’s parameter count, but it is rumored to be in the neighborhood of 1 trillion.
GPT stands for Generative Pretrained Transformer – generative because these models excel at generating text. Not only can they translate “hello world” to French, but they can also translate “Write a short story about three young people attending a wizarding school” into fully formed prose. GPT-3 was trained with roughly half a trillion words from Common Crawl, WebText, Wikipedia, and a corpus of books. (OpenAI hasn’t revealed how long it took to train GPT-3, but they have said that they used a distributed training process with 1,728 NVIDIA V100 GPUs hosted in Microsoft Azure.) It was also trained to respond to natural-language prompts such as “Describe molecular biology in the style of Dr. Seuss” or “Translate hello world into French.” Unlike BERT, GPT models can perform certain NLP tasks such as text translation and question-answering without fine-tuning, a feat known as zero-shot or few-shot learning. OpenAI documented this in a seminal 2020 paper titled “Language Models are Few-Shot Learners.”
ChatGPT is a fine-tuned version of GPT-3.5, which itself is a fined-tuned version of GPT-3. At its heart, ChatGPT is a transformer encoder-decoder that responds to prompts by iteratively predicting the first word in the response, then the second word, and so on – much like a transformer that translates English to French. The diagram below shows how ChatGPT might respond to the prompt “Complete the sentence every good.” Like a text translator, it generates each word in the response one word at a time, and it determines what the next word should be based on probabilities derived from the vast corpus of text it was trained on and the text it has generated so far. In this example, it picks the highest-ranking word every time, yielding the response “every good thing must come to an end.”
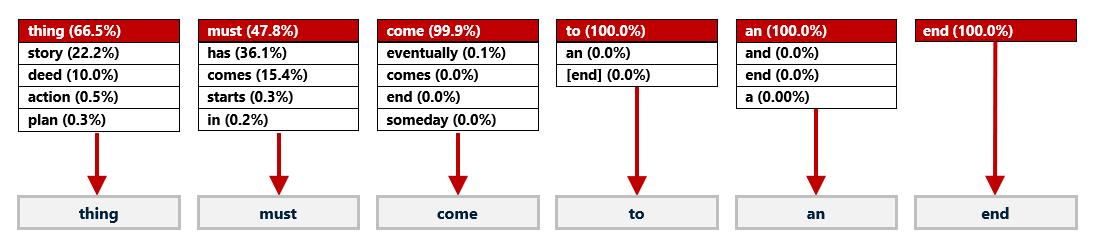
How ChatGPT completes a sentence with temperature=0.0
Picking the top-ranking word in each iteration works fine for short responses, but it can make longer responses feel stiff and unimaginative. That’s why ChatGPT offers various knobs and dials that you can adjust to alter how it selects words. One of these is the temperature setting. If temperature=0, ChatGPT selects the word with the highest probability in each iteration. But if you raise temperature to, say, 0.7, ChatGPT sometimes picks words lower in the list, yielding text that often feels more natural and creative. This is illustrated below, where a non-zero temperature setting yields “every good thing has its price” from the same input prompt.

How ChatGPT completes a sentence with temperature=0.7
ChatGPT is a glorified word predictor. It isn’t sentient. It doesn’t know what it’s saying, and yes, you can coax it into admitting that it wants to take over the world or saying hurtful things (although it was specially conditioned during training to try to suppress such output). It’s simply stringing words together using an expansive statistical model built from billions of sentences.
Speaking of conditioning: ChatGPT was trained in three phases. First, the base model, GPT-3.5, was trained with more than 10,000 sample prompts and responses. Next, it was asked to generate several responses to each of tens of thousands of prompts, and a team of contractors graded each response for accuracy, appropriateness, and other criteria, assigning lower grades, for example, to responses that were inaccurate, unhelpful, or hurtful. Finally, the model was tweaked to favor higher-ranked responses. Out of this came ChatGPT as we know it today.
One of the more remarkable aspects of ChatGPT is that when you ask it a question, it doesn’t crawl the Internet to find an answer. The entire body of knowledge present on the Internet in September 2021 (and then some) was baked into those 175 billion parameters during training. It’s akin to you answering a question off the top of your head rather than reaching for your phone and Googling for an answer. When Microsoft incorporated GPT-4 into Bing, they added a separate layer providing Internet access. OpenAI did the same with WebGPT, a GPT-3 variant. ChatGPT neither needs nor has that capability.
ChatGPT was also trained on billions of lines of code from the world’s most popular source-code repository, GitHub, which is why it’s able to generate code as well as prose. This begs the question: Is it fair – and legal – to train a deep-learning model that “learns” from code written by others? Especially when much of that code is governed by open-source licenses that require attribution when used? That’s the billion-dollar question, and it’s the subject of a class-action lawsuit filed against Microsoft, GitHub, and OpenAI last year. It’s too early to tell how it will turn out, but it’s not too dramatic to say that the future of AI (and of writers, programmers, and artists as well) could hang in the balance. AI, after all, is nothing without vast amounts of data to train on.
The ChatGPT API
On March 1st, 2023, OpenAI made ChatGPT available through a REST API, making it possible for programmers to infuse ChatGPT’s intelligence into their own code. The following example, written in Python, uses the ChatGPT API to answer the question “In which academic paper was the deep learning transformer introduced, and where can I find it?”
messages = [{
'role': 'user',
'content': 'In which academic paper was the deep learning transformer '
'introduced, and where can I find it?'
}]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
ChatGPT responded as follows:
The deep learning transformer was introduced in the academic paper titled “Attention Is All You Need” published in 2017 by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. The paper is available on the arXiv preprint server: https://arxiv.org/abs/1706.03762.
I’ll introduce the ChatGPT API and some of the amazing things you can do with it in subsequent posts. For now, I’ll close with a description of ChatGPT written by ChatGPT:
ChatGPT is a language model developed by OpenAI that uses the GPT-3.5 architecture to generate human-like responses to a wide range of topics. Trained on vast amounts of text from the internet, books, and other sources, ChatGPT can understand and generate natural language, engaging in conversations with people to provide informative and helpful responses. Its ability to understand context, infer meaning, and generate coherent and relevant responses makes it a powerful tool for a variety of applications, from language translation and customer service to personal assistants and creative writing. Continuously learning and improving through updates and refinements to its algorithms and training data, ChatGPT is an advanced technology that is changing the way we interact with computers and artificial intelligence.
I couldn’t have said it better myself. In my next post, you will learn about the ChatGPT API.