People the world over are using ChatGPT to transform the way they do business. Sales executives use it to create scoping documents from transcripts of conversations with clients. Marketing directors use it to generate ad copy, while programmers use it to write snippets of code. I recently needed to generate an array of 1s and 0s from the alpha channel in a PNG image. Rather than consult Stack Overflow, I typed “Write Python code that opens a PNG file and creates a NumPy array of 1s and 0s in which 0s correspond to fully transparent pixels” into the ChatGPT Web site, and a few seconds later, I had three succinct lines of code (not including imports) that did precisely what I asked. If that’s not transformative, I don’t know what is.
It’s simple enough to leverage ChatGPT by typing commands into a Web site, but ChatGPT exposes a REST API that makes it possible to infuse its intelligence into your apps. Imagine writing tools that translate product manuals to other languages, convert VB.NET code to C#, or put a ChatGPT front end on your company’s SharePoint documents. The ChatGPT API makes all this more possible.
Your First ChatGPT Application
So what is the ChatGPT API, and how do you leverage it in your code? Let’s jump right in with a Python app that translates “Hello, world” into French:
import openai
openai.api_key = 'OPENAI_KEY'
messages = [{
'role': 'user',
'content': 'Translate the following text from English to French: '
'Hello, world'
}]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
The first statement imports the OpenAI Python library, which offers an easy-to-use Python interface to the ChatGPT API. For the import to work, you must install the package in your environment:
pip install openai
The second statement provides your OpenAI API key to the library. After creating an OpenAI account on the OpenAI Web site or logging in if you already have one, go to the API keys page, generate an API key, and substitute it for OPENAI_KEY in the code above. Then save the key in a secure place where you can easily retrieve it later. Once generated, an API key can’t be retrieved by returning to the OpenAI Web site. If you lose an API key, your only recourse is to generate a new one.
The next statement creates an array of Python dictionaries – in this case, an array of one – named messages containing the command, or prompt, that you wish ChatGPT to execute and the originator of that prompt (user). Under the hood, the array is converted into a markup language called ChatML. I’ll say more about ChatML in the next section, but for now shift your attention to the next few lines:
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
This is the statement that places a call over the Internet to ChatGPT. The model parameter identifies the deep-learning model that’s the target of the call; “gpt-3.5-turbo” is ChatGPT. The messages parameter identifies the array of dictionaries containing the prompt. If the call is successful, the print statement on the final line outputs the result:
Bonjour, monde
Your results may differ, but most of the time, ChatGPT translates “Hello, world” into “Bonjour, monde.” If you want consistent results from run to run, add a temperature=0 parameter to the call:
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages,
temperature=0
)
If you read the previous post in this series, you know that temperature controls the level of randomness used to predict the next word in ChatGPT’s output. Lower values favor consistency over creativity.
The openai package provides a Python interface to ChatGPT, but other packages exist for other languages. Here’s the C# equivalent of the example above. It relies on a NuGet package named OpenAI that provides a .NET interface to ChatGPT and other OpenAI models:
var openai = new OpenAIAPI("OPENAI_KEY");
var messages = new ChatMessage[]
{
new ChatMessage(
ChatMessageRole.User,
"Translate the following text from English to French: Hello, world"
)
};
var result = await openai.Chat.CreateChatCompletionAsync(
model: Model.ChatGPTTurbo,
messages: messages
);
Console.WriteLine(result);
At the time of this writing, neither Microsoft nor OpenAI has published an official NuGet package for ChatGPT, but several third-party packages are available. As the ChatGPT ecosystem grows, so, too, does the number of packages that wrap the ChatGPT API and make it easily accessible from a variety of platforms and programming languages.
The Chat Markup Language (ChatML)
Before ChatGPT, there was GPT-3. Using the GPT-3 API to execute a simple prompt looks like this:
response = openai.Completion.create(
engine='text-davinci-003',
prompt='Describe molecular biology in the style of Dr. Seuss'
)
The prompt parameter contains the command that you want GPT-3 to execute, while the engine parameter identifies a GPT-3 model. “text-davinci-003” is the most capable version of GPT-3, as well as the most expensive: about 10 times the cost of ChatGPT for each word generated.
ChatGPT replaces the prompt parameter with the messages parameter, which carries instructions for ChatGPT in ChatML format. One use for ChatML is providing instructions telling ChatGPT how to behave. As an example, try running the code below. I’ve omitted the statement that assigns the API key; from now on, that will be assumed:
messages = [{
'role': 'user',
'content': 'My name is Jeff. What's your name?'
}]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
ChatGPT is likely to respond with something like “I am a chatbot, so I don’t have a name.” But now try this example:
messages = [
{
'role': 'system',
'content': 'You are a friendly chatbot named Bot'
},
{
'role': 'user',
'content': 'My name is Jeff. What's your name?'
}
]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
This time, ChatGPT responds “Hello Jeff, my name is Bot. Nice to talk to you today!” You can be as specific as you’d like with system messages, even saying “If you don’t know the answer to a question, say I don’t know.” You can also prescribe a persona. Replace “friendly” with “sarcastic” in the message from system and run the code again. The response may be “Oh, hi Jeff, I’m Bot. You can call me whatever you’d like, but don’t call me late for dinner.” Run the code several times and there’s no end to the colorful responses you’ll receive.
ChatML’s greatest power lies in persisting context from one call to the next. As an example, try this:
messages = [
{
'role': 'system',
'content': 'You are a friendly chatbot named Bot'
},
{
'role': 'user',
'content': 'My name is Jeff. What's your name?'
}
]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
Then follow up immediately with this:
messages = [
{
'role': 'system',
'content': 'You are a friendly chatbot named Bot'
},
{
'role': 'user',
'content': 'What is my name?'
}
]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
ChatGPT will respond with something along the lines of “I’m sorry, but I don’t have access to your personal information or your name.” But now try this:
messages = [
{
'role': 'system',
'content': 'You are a friendly chatbot named Bot'
},
{
'role': 'user',
'content': 'My name is Jeff. What's your name?'
},
{
'role': 'assistant',
'content': 'Hello Jeff, my name is Bot. Nice to meet you!'
},
{
'role': 'user',
'content': 'What is my name?'
}
]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
How does ChatGPT respond this time? Hopefully with “Your name is Jeff, as you mentioned earlier” or something similar. Get it? Calls to ChatGPT are stateless. If you give ChatGPT your name in one call and ask it to repeat your name in the next call, ChatGPT has no clue. But with ChatML, you can provide past ChatGPT responses as context for the current call. You could easily build a conversational bot simply by repeating the last few prompts and responses in each call to ChatGPT. The further back you go, the longer the chatbot’s “memory” will be.
Counting Tokens
In my article introducing ChatGPT, I described how ChatGPT responds to commands by predicting one word, then the next, and so on. I also simplified things a bit. ChatGPT doesn’t predict words; it predicts tokens, which are whole words or partial words (“subwords”). Tokenization plays an important role in Natural Language Processing. Neural networks can’t process text, at least not directly; they only process numbers. Tokenization converts words into numbers that a deep-learning model can understand. When ChatGPT generates a response by predicting a series of tokens, the tokenization process is reversed to convert the tokens into human-readable text.
ChatGPT uses a form of tokenization called Byte-Pair Encoding (BPE), which was developed in the 1990s as a mechanism for compressing text. Today, it is widely used in the NLP space. Here’s how ChatGPT BPE-tokenizes the phrase “fourscore and seven years ago:”
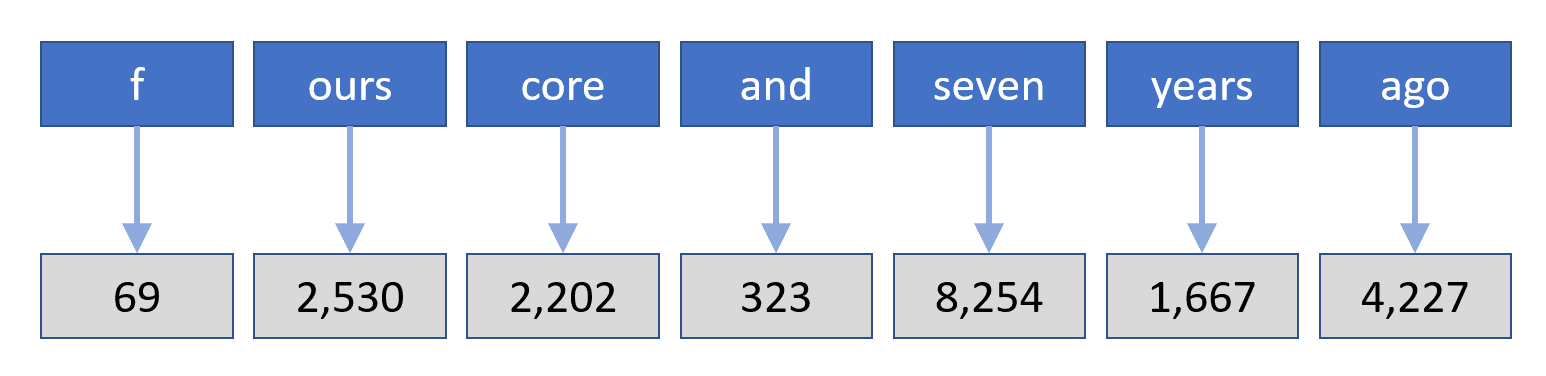
Phrase tokenized using Byte-Pair Encoding
The numbers are indexes into a vocabulary of tokens maintained by ChatGPT. If you’d like to know more about BPE and how it works, check out the article titled “Byte-Pair Encoding Tokenization” from Hugging Face. Another great resource is “Byte-Pair Encoding: Subword-Based Tokenization Algorithm” by Chetna Khanna.
As a rule of thumb, 3 words on average translate to about 4 BPE tokens. That’s important because ChatGPT limits the number of tokens in each API call. The maximum token count is controlled by a parameter named max_tokens. For ChatGPT, the default is 2,048 tokens or about 1,500 words, and the upper limit is 4,096. (GPT-4 expands the maximum token count to 32,768.) This limit applies to the combined length of the input and output in each API call. If the number of tokens exceeds max_tokens, then either the call will fail or the response will be truncated. The following statement calls ChatGPT and raises the maximum token count to 4,096:
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages,
max_tokens=4096
)
There are a couple of reasons to be aware of the token count in each call. First, you’re charged by the token for input and output. The price at the time of this writing was 0.2 cents per 1,000 tokens, which equates to 500,000 tokens – or roughly 375,000 words – per U.S. dollar. The larger the messages array and the longer the response, the more you pay. Second, when using the messages array to provide context from previous calls, you have a finite amount of space to work with. It’s common practice to pick a number – say, 5 or 10 – and limit the context from previous calls to that number of messages, or to programmatically compute the number of tokens that a conversation comprises and include as many messages as max_tokens will allow while leaving room for the response.
You can compute the number of tokens generated from a text sample with help from a Python package named tiktoken:
import tiktoken
text = 'Jeff loves to build and fly model jets. He built his first '
'jet, a BVM BobCat, in 2007. After that, he built a BVM Bandit, '
'a Skymaster F-16, and a Skymaster F-5. The latter two are 1/6th'
'scale models of actual fighter jets. Top speed is around 200 MPH.'
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
num_tokens = len(encoding.encode(text))
print(f'{num_tokens} tokens')
The answer should be 78, which corresponds in this case to 49 words. You can estimate the token count for an entire messages array with the following code, which was adapted from comments and all from the ChatGPT documentation:
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}n{content}<im_end>n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
print(f'{num_tokens} tokens')
The comments refer to the raw ChatML generated from the messages array and passed over the wire to ChatGPT. Be aware that ChatML is almost certain to evolve over time, so the code you write today might have to be modified for future versions of ChatGPT.
After a call to the ChatGPT API completes, the return value reveals the token count (and therefore how many tokens you’ll be charged for). Here’s an example:
messages = [{
'role': 'user',
'content': 'Translate the following text from English to German: '
'Hello, world'
}]
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(f'Result: {response.choices[0].message.content}')
print(f'Input tokens: {response.usage.prompt_tokens}')
print(f'Output tokens: {response.usage.completion_tokens}')
print(f'Total tokens: {response.usage.total_tokens}')
print(f'Reason: {response.choices[0].finish_reason}')
The output is as follows:
Result: Hallo, Welt Input tokens: 20 Output tokens: 3 Total tokens: 23 Reason: stop
The final line reveals how the call completed: “stop” if it completed normally, or “length” if the output was truncated because it would have exceeded max_tokens. Another possible value is “content_filter,” which indicates that some content was omitted because it was flagged as inappropriate by OpenAI’s content-moderation filters.
Streaming Completions
By default, calls to ChatCompletion.create don’t return until the entire response has been generated. However, you can include a stream=True parameter in the call and “chunk” the response, showing results as they become available. Here’s an example that writes a short story and displays the output streamed back from ChatGPT:
messages = [{
'role': 'user',
'content': 'Write a short story that begins with '
'"It was a dark and stormy night"'
}]
chunks = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages,
stream=True
)
for chunk in chunks:
content = chunk['choices'][0].get('delta', {}).get('content')
if content is not None:
print(content, end='')
The ChatGPT Web site uses this technique to show text as it’s generated in real time. Run this code in a Jupyter notebook and you’ll find that it delivers a similar user experience.
Handling Errors
In a perfect world, API calls to ChatGPT would never fail. In reality, they can fail for a variety of reasons – for example, if you pass an invalid API key, if you exceed the maximum token count or OpenAI’s built-in rate limits, or if the ChatGPT servers are simply overloaded. Robust code anticipates these errors and responds gracefully when they occur.
The OpenAI Python library defines several exception types that can be thrown when a call fails. An AuthenticationError exception, for example, indicates that the API key is invalid, while ServiceUnavailableError tells you that ChatGPT is temporarily unavailable. (It happens.) You can use Python’s standard exception-handling mechanism to catch these exceptions and respond to them in kind. Here’s an example that responds to AuthenticationError and ServiceUnavailableError exceptions with specific error messages and uses a generic handler to respond to other exceptions:
from openai.error import AuthenticationError, ServiceUnavailableError
messages = [{
'role': 'user',
'content': 'Translate the following text from English to French: '
'Hello, world'
}]
try:
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(response.choices[0].message.content)
except AuthenticationError as e:
print('Invalid API key')
except ServiceUnavailableError as e:
print('ChatGPT temporarily unavailable')
except Exception as e:
print('Call failed')
In the face of rate-limit or service-unavailable errors, you could implement retry logic that repeats the call after a short delay. However, you choose to go about it, keep in mind that production code shouldn’t allow exceptions to leak through. Uncaught exceptions, after all, bring down applications.
Next Up
Now that you’re familiar with the mechanics of the ChatGPT API, my next article will focus on some of the cool things you can do with it. ChatGPT is a game-changer when it comes to infusing AI into the apps that you write, and the ChatGPT API is the mechanism that makes it possible.
Learn more about our Azure services