This is a continuation of my series of posts on Databricks where we most recently reviewed the Workspace & Notebooks. Now let’s get more familiar with the concept of clusters.
{kind=link}
Clusters
Databricks breaks clusters into multiple categories:
- All-Purpose Clusters
- Job Clusters
- Pools
Spark clusters consist of a single driver node and multiple worker nodes. The type of hardware and runtime environment are configured at the time of cluster creation and can be modified later. It is best to configure your cluster for your particular workload(s).
Databricks provides many benefits over stand-alone Spark when it comes to clusters. There are a plethora of node sizes as well as the ability to horizontally scale as a workload changes. Pools are also available which cut out the cluster start & auto-scaling times by providing a set of hot spare instances.
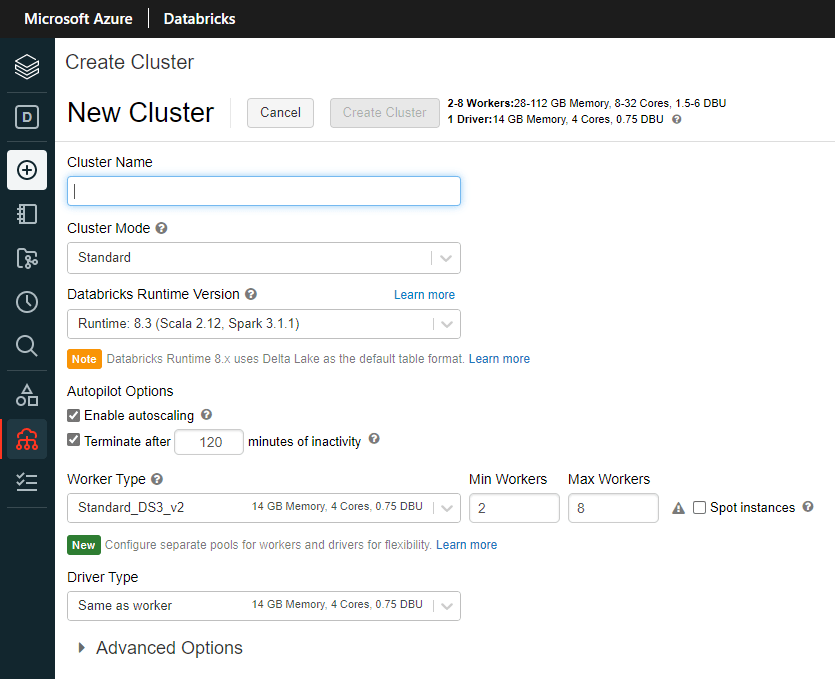
The above new cluster tab within the workspace allows for full configuration. Your cluster(s) can also be defined by code and deployed as part of your deployment pipeline(s).
From the New Cluster GUI, name your cluster and choose a Cluster Mode. Standard is the default and most used mode. A single node cluster can be good for development or testing and High Concurrency is for when multiple workloads are going to be using the cluster.
The Databricks Runtime Version you choose is very important as some features are only supported in certain versions. I recommend using an LTS version for production workloads. Check the Databricks Release page frequently to stay up to date with the latest runtimes and associated features.
Nodes
Nodes are the discrete compute power used for your cluster. There is one driver and n workers. Enabling autoscaling is recommended and allows you to specify a minimum and a maximum number of worker nodes.
Begin with the smallest (default) Worker and Driver Types (Standard_DS3_v2 at time of writing). After you’ve developed your pipeline you can return to optimize your cluster size for your workload. Check the Spot instances checkbox to further reduce cost.
A future post will get into monitoring your cluster but for now, you should be ready to start developing in Databricks. The next post will be on Jobs and after that different ways of running notebooks (batch or streaming).