Scikit-learn is arguably the world’s most popular machine-learning framework. The efficacy of the library, the documentation that accompanies it, and the mindshare that surrounds it are the primary reasons more ML models are written in Python than any other language. But Scikit isn’t the only machine-learning framework. Others exist for other languages, and if you can write an ML model in the same programming language as the client that uses it, you can avoid jumping through some of the hoops described in my previous post to operationalize the model.
My favorite programming language is C#. While there are a lot of things I like about Python, much of the application-development work that my company does for customers is done in C#. When these solutions involve ML and AI, we frequently use ML.NET for the machine-learning components. ML.NET is Microsoft’s free, open-source, cross-platform machine-learning library for .NET developers. It does most of what Scikit does and a few things that Scikit doesn’t. And when it comes to writing ML/AI solutions in C#, there is no better tool for the job.
ML.NET is a relatively new to the public, but it derives from an internal library that was developed by Microsoft – and used in Microsoft products – for more than a decade. The ML algorithms that it implements have been tried and tested in the real world and tuned to optimize performance and accuracy. Because ML.NET is consumed from C#, you get all the benefits of a compiled programming language, including type safety and fast execution.
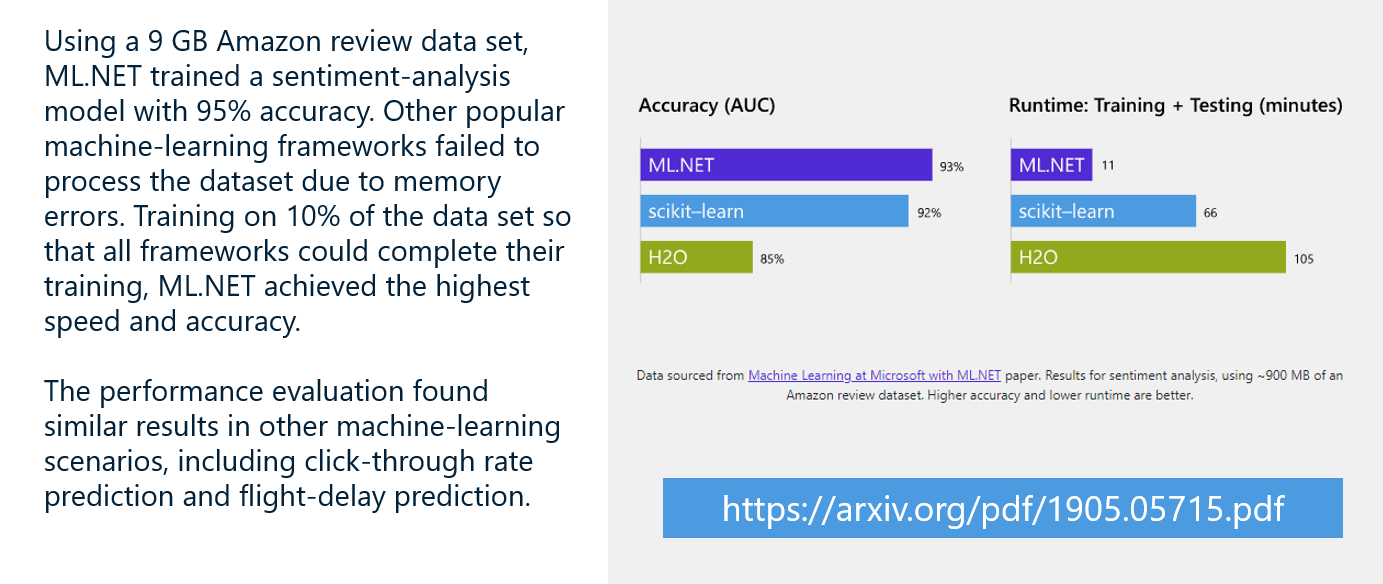
The chart below comes from a paper published by the ML.NET team at Microsoft. It shows how ML.NET compared to other libraries when applied to a massive sentiment-analysis dataset. ML.NET required 1/6th the training time of Scikit, and the dataset had to be reduced in size for Scikit to even be able to consume it.
ML.NET is compatible with Windows, Linux, and macOS. Thanks to an innovation called IDataView, it can handle datasets of virtually unlimited size. While it can’t be used to build neural networks from scratch, it does have the ability to load existing neural networks and use a technique called transfer learning to repurpose those networks to solve domain-specific problems. (I will cover transfer learning in detail in a future blog post.) It can also be consumed in Python and even combined with Scikit-learn using a set of Python bindings called NimbusML.
If you’re a .NET developer who is interested in machine learning, there has never been a better time to get acquainted with ML.NET. This post isn’t meant to provide an exhaustive treatment of ML.NET, but to introduce it, show the basics of building ML models with it, and hopefully whet your appetite enough to motivate you to learn more on your own. There are plenty of great resources available online, including the official ML.NET documentation, a GitHub repo containing ML.NET samples, and the ML.NET cookbook.
Sentiment Analysis with ML.NET
The C# code below uses ML.NET to build and train a sentiment-analysis model. It’s equivalent to the Python example I presented in my post on sentiment analysis with Scikit-learn:
var context = new MLContext(seed: 0);
// Load the data
var data = context.Data.LoadFromTextFile("reviews.csv",
hasHeader: true, separatorChar: ',', allowQuoting: true);
// Split the data into a training set and a test set
var trainTestData = context.Data.TrainTestSplit(data,
testFraction: 0.2, seed: 0);
var trainData = trainTestData.TrainSet;
var testData = trainTestData.TestSet;
// Build and train the model
var pipeline = context.Transforms.Text.FeaturizeText
(outputColumnName: "Features", inputColumnName: "Text")
.Append(context.BinaryClassification.Trainers.SdcaLogisticRegression());
var model = pipeline.Fit(trainData);
// Evaluate the model
var predictions = model.Transform(testData);
var metrics = context.BinaryClassification.Evaluate(predictions);
Console.WriteLine($"AUC: {metrics.AreaUnderPrecisionRecallCurve:P2}");
// Score a line of text for sentiment
var predictor = context.Model.CreatePredictionEngine(model);
var input = new Input { Text = "Among the best movies I have ever seen"};
var prediction = predictor.Predict(input);
Console.WriteLine($"Sentiment score: {prediction.Probability}");
Every ML.NET app begins by creating an instance of the MLContext class. The seed parameter initializes the random-number generator used by ML.NET so you get repeatable results from one run to the next. MLContext exposes a number of properties through which large parts of the ML.NET API are accessed. You see an example of this in the call to LoadFromTextFile, which is a DataOperationsCatalog method accessed through MLContext’s Data property.
LoadFromTextFile is one of several methods ML.NET provides for loading data from text files, databases, and other data sources. It returns a data view, which is an object that implements the IDataView interface. Data views in ML.NET are similar to DataFrames in Pandas, with one important difference. Whereas DataFrames have to fit in memory, data views do not. Internally, data views use a SQL-like cursor to access data. This means they can wrap a theoretically unlimited amount of data. That’s why ML.NET was able to process the entire Amazon dataset referenced in the chart above, while Scikit was not.
After loading the data and splitting it for training and testing, the code above creates a pipeline containing a TextFeaturizingEstimator object (created with the FeaturizeText method) and an SdcaLogisticRegressionBinaryTrainer object (created by the SdcaLogisticRegression method). This is analogous in Scikit to creating a pipeline containing a CountVectorizer for vectorizing input text and a LogisticRegression object for fitting a model to the data. Calling Fit on the pipeline trains the model, just like calling fit in Scikit. It’s no coincidence that ML.NET employs some of the same patterns as Scikit-learn. This was done intentionally to impart a sense of familiarity to programmers who already know Scikit.
After evaluating the model’s accuracy by computing the area under the precision-recall curve, a call to ModelOperationsCatalog.CreatePredictionEngine creates a prediction engine, whose Predict method is called to make a prediction. Unlike Scikit, which has you call predict on the estimator itself, ML.NET encapsulates prediction capability in a separate object, in part so that multiple prediction engines can be created to achieve scalability in high-traffic scenarios.
Predict accepts an Input object as input and returns an Output object. One of the benefits of building models with ML.NET is strong typing. Observe that LoadFromTextFile is a generic method that accepts a class name as a type parameter – in this case, Input. Similarly, CreatePredictionEngine uses type parameters to specify schemas for input and output. The Input and Output classes are application-specific and in this instance are defined as follows:
public class Input
{
[LoadColumn(0)]
public string Text;
[LoadColumn(1), ColumnName("Label")]
public bool Sentiment;
}
public class Output
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
public float Probability { get; set; }
}
The LoadColumn attributes map columns in the data file to properties defined in the Input class. In this example, they tell ML.NET that values for the Text field come from column 0 in the input file, and values for Sentiment (the 1s and 0s indicating whether the sentiment expressed in the text is positive or negative) come from column 1. The ColumnName(“Label”) attribute identifies the second column as the label column – the one containing the values that the model will attempt to predict.
The Output class defines the output schema. In this example, it contains properties named Prediction and Probability, which, following a prediction, hold the predicted label (0 or 1) and the probability that the sample belongs to the positive class. Here, that probability doubles as a sentiment score. The ColumnName(“PredictedLabel”) attribute maps the value predicted by the Predict method to the Output object’s Prediction property.
In case you wondered, there is nothing magic about the class names Input and Output. You could name them SentimentData and SentimentPrediction and the code would work just the same.
In my previous post, you learned how to use Python’s pickle module to save and load trained models. You do the same in ML.NET by calling ModelOperationsCatalog.Save and ModelOperationsCatalog.Load through the MLContext object’s Model property:
// Save a trained model to a local zip file
context.Model.Save(model, data.Schema, "model.zip");
// Load a trained model from a local zip file
var model = context.Model.Load("model.zip", out DataViewSchema schema);
This enables clients to recreate a model in its trained state and use it to make predictions without having to train the model again.
Image Classification with ML.NET
The preceding example illustrates the basics of ML.NET and lends itself to an apples-to-apples comparison of ML.NET and Scikit. But there is much more that you can do with ML.NET, as the next example demonstrates.
One of the tasks at which machine learning excels is image classification: analyzing an image and determining, for example, whether it contains a dog or a cat. You saw one form of image classification at work in my post on support-vector machines, which used an SVM to perform facial recognition. State-of-the-art image classification today is almost always performed with neural networks. Microsoft, Google, and others have trained sophisticated neural networks that can recognize thousands of different objects from basketballs to butterflies on expensive GPU clusters and published them so others can use them, too. With transfer learning, you can modify these networks to recognize objects that they weren’t originally trained to recognize, and you can do so on an ordinary PC. This has a variety of practical implications, from identifying defective parts coming off an assembly line to recognizing when a person steps in front of a self-driving car.
You can implement transfer learning with deep-learning libraries such as TensorFlow and Keras. But in my opinion, no library makes transfer learning easier than ML.NET. To demonstrate, I wrapped ML.NET around a sophisticated neural network trained by Microsoft Research and retrained it to distinguish between images of hot dogs, pizza, and sushi. I used just 60 images in total – 20 each of the three classes – that I found on the Internet. Here’s a sample of the training images:

Once the training images were loaded, building and training the model (including loading the pretrained neural network) required just two lines of code thanks to ML.NET’s ImageClassificationTrainer class:
var pipeline = context.MulticlassClassification.Trainers.ImageClassification(options)
.Append(context.Transforms.Conversion.MapKeyToValue(_predictedLabelColumnName));
var model = pipeline.Fit(trainData);
Training time was less than 2 minutes on a desktop PC without a GPU assist. After training, I saved the model in a zip file. Then I built a Windows WPF client that loads the model and uses it to analyze images selected by the user. Here’s how it responded to a photo I took last summer when I grilled hot dogs on my deck:
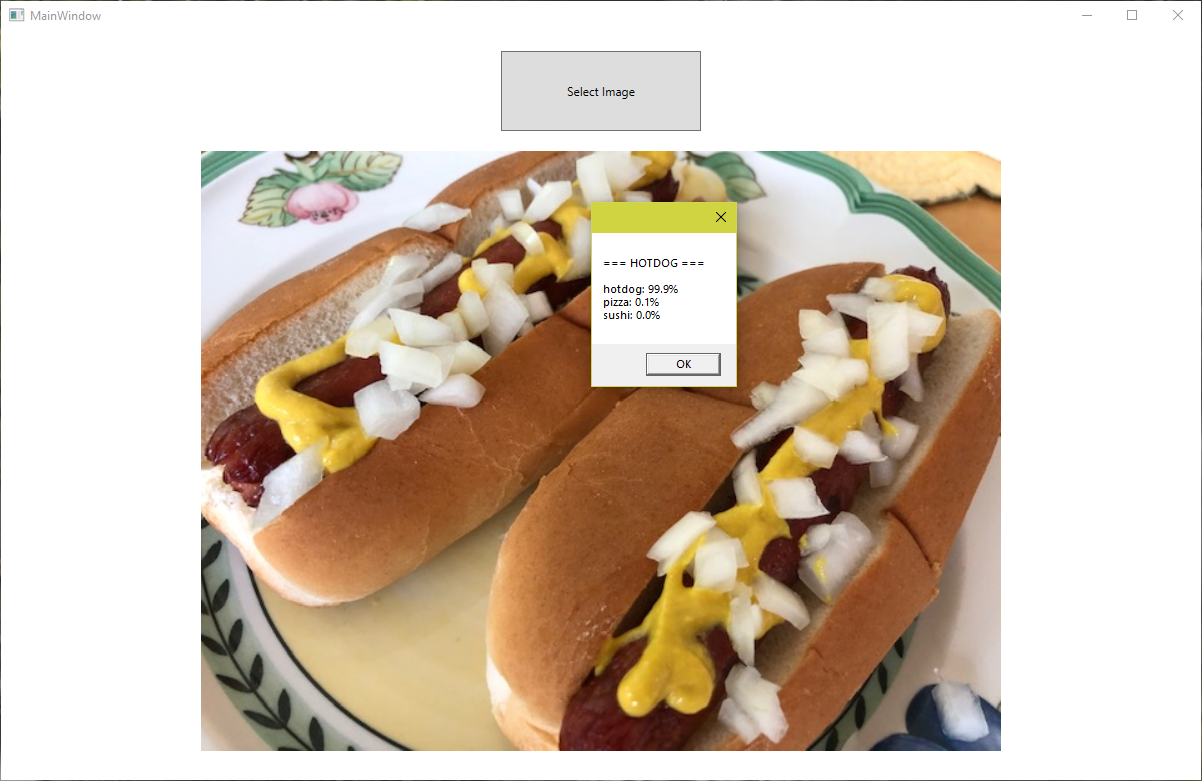
The model predicted with 99.9% certainty that the photo contains a hot dog. Just imagine trying to build an app like this that relies on conventional software algorithms rather than machine learning to determine whether a photo contains a hot dog. This is a great example of how machine learning and AI make things possible in software that would be difficult or impossible otherwise. And it’s a teaser for where we’re going in the next several posts in this series.
I won’t walk through the source code because we’ve yet to cover neural networks and transfer learning. You can download these samples and others (including the sentiment-analysis example in the previous section) from the public ML.NET repo that I maintain on GitHub. The code that builds the model is in the project named “MLN-ImageClassification,” while the code that consumes the model is in “MLN-NotHotDog.” Later, after I’ve introduced transfer learning, you might find it useful to circle back and have another look. I think you’ll agree that ML.NET makes a complicated process somewhat easy. And the code will make a lot more sense once you understand what transfer learning is and how it works.
Where We Are (and Where We’re Going)
This is the 15th post in a series of posts introducing ML and AI to software developers and engineers. For convenience, here are all 15 posts in order:
- Machine Learning and AI for Software Developers
- Unsupervised Learning with k-Means Clustering
- Supervised Learning with k-Nearest Neighbors
- Regression Algorithms
- Regression Modeling
- Binary Classification
- Binary Classification: Sentiment Analysis
- Binary Classification: Spam Filtering
- Multiclass Classification
- Support-Vector Machines
- Principal Component Analysis
- PCA-Based Anomaly Detection
- Recommender Systems
- Operationalizing Machine-Learning Models
- Building Machine-Learning Models with ML.NET
These posts teach the basics of machine learning and lean heavily on Scikit-learn. In my next post, we’ll shift gears and begin exploring deep learning with neural networks. Deep learning is a subset of machine learning that expands the boundaries of what’s possible with ML and AI. Think you’ve seen some cool stuff so far? Just wait. The fun is just getting started.